Welcome back to our series of case studies of research funders using the Grant Linking System. In this interview, I talk with Cátia Laranjeira, PTCRIS Program Manager at FCCN|FCT, Portugal’s main public funding agency, about the agency’s approach to metadata, persistent identifiers, Open Science and Open Infrastructure.
With a holistic approach to the management, production and access to information on science, FCCN|FCT’s decision to implement the Grant Linking System within their processes was not simply a technical upgrade, but a coordinated effort to continue building a strong culture of openness. With the mantra “register once, reuse always”, FCCN|FCT efforts to embrace open funding metadata was only logical.
Repositories are home to a wide range of scholarly content; they often archive theses, dissertations, preprints, datasets, and other valuable outputs. These records are an important part of the research ecosystem and should be connected to the broader scholarly record. But to truly serve their purpose, repository records need to be connected to each other, to the broader research ecosystem, and to the people behind the research. Metadata is what makes that possible. Enhancing metadata is a way to tell a fuller, more accurate story of research. It helps surface relationships between works, people, funders, and institutions, and allows us as a community to build and use a more connected, more useful network of knowledge - what Crossref calls the ‘Research Nexus’.
The Crossref Grant Linking System (GLS) has been facilitating the registration, sharing and re-use of open funding metadata for six years now, and we have reached some important milestones recently! What started as an interest in identifying funders through the Open Funder Registry evolved to a more nuanced and comprehensive way to share and re-use open funding data systematically. That’s how, in collaboration with the funding community, the Crossref Grant Linking System was developed. Open funding metadata is fundamental for the transparency and integrity of the research endeavour, so we are happy to see them included in the Research Nexus.
Lots of exciting innovations are being made in scientific publishing, often raising fundamental questions about established publishing practices. In this guest post, Ludo Waltman and André Brasil discuss the recently launched MetaROR publish-review-curate platform and the questions it raises about good practices for Crossref DOI registration in this emerging landscape.
To work out which version you’re on, take a look at the website address that you use to access iThenticate. If you go to ithenticate.com then you are using v1. If you use a bespoke URL, https://crossref-[your member ID].turnitin.com/ then you are using iThenticate 2.0.
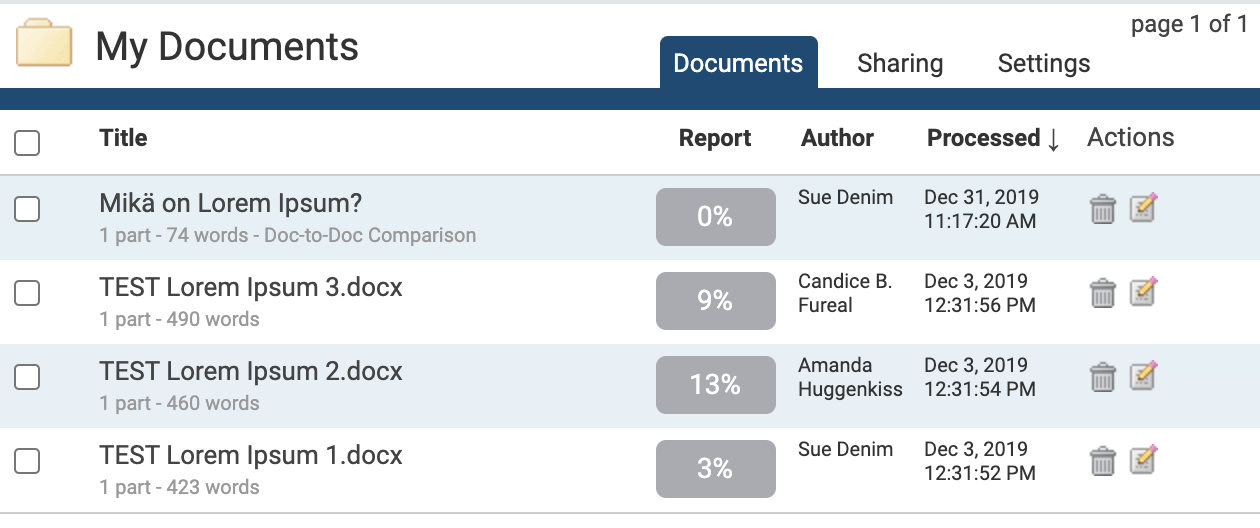
Within a folder, the Documents tab shows all the submitted documents for that folder.
Each document submitted generates a Similarity Report after the document has been through the Similarity Check. If more documents are present than can be displayed at once, the pages feature will appear beneath the documents - click the page number to display, or click Next to move to the next page of documents.
zip file upload - to submit a zip file containing multiple documents, up to a maximum of 100MB or 1,000 files. Larger files may take longer to upload
cut & paste - to submit text directly into the submission box. Use this to copy and paste a submission from a file format that is not supported. This method supports plain text only (no images or non-text information)
iThenticate currently accepts the following file types for document upload:
Microsoft Word® (.doc and .docx)
Word XML
plain text (.txt)
Adobe PostScript®
Portable Document Format (.pdf)
HTML
Corel WordPerfect® (.wpd)
Rich Text Format (.rtf)
Each file may not exceed 400 pages, and each file size may not exceed 100 MB. Reduce the size of larger files by removing non-text content. You can’t upload or submit to iThenticate files that are password-protected, encrypted, hidden, system files, or read-only.
.pdf documents must contain text - if they contain only images of text, they will be rejected during the upload attempt. To check, copy and paste a section of the .pdf into a plain-text editor such as Microsoft Notepad® or Apple TextEdit®. If no text is copied over, the selection does not contain text.
To convert scanned images of a document, or an image saved as a .pdf, use Optical Character Recognition (OCR) software to convert the image to text. The conversion software can introduce errors, so manually check and correct the converted document.
Some document formats can contain multiple data types, such as text, images, embedded information from another file, and formatting. Non-text information that is not saved directly within the document will not be included in a file upload, for example, references to a Microsoft Excel® spreadsheet included within a Microsoft Office Word® document.
Use a word-processing program to save your file as one of the accepted types listed above, such as .rtf or .txt. Neither file type supports images or non-text data within the file. Plain text format does not support any formatting, and rich text format allows only limited formatting.
When converting a file to a new format, save it with a different name from the original, to avoid accidentally overwriting the original file. This is especially important when converting to plain text or rich text formats, to prevent permanent loss of the original formatting or image content of the file.
Page maintainer: Kathleen Luschek Last updated: 2020-May-19